
Learning net Development: A Love-Hate Relationship
페이지 정보

본문
 Open-sourcing the new LLM for public research, free deepseek AI proved that their DeepSeek Chat is a lot better than Meta’s Llama 2-70B in numerous fields. Trying multi-agent setups. I having another LLM that can right the primary ones errors, or enter into a dialogue where two minds reach a greater final result is completely attainable. ARG occasions. Although DualPipe requires holding two copies of the mannequin parameters, this doesn't considerably enhance the reminiscence consumption since we use a big EP measurement throughout training. ARG affinity scores of the specialists distributed on each node. Slightly completely different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid operate to compute the affinity scores, and applies a normalization among all chosen affinity scores to supply the gating values. Like the machine-limited routing utilized by DeepSeek-V2, DeepSeek-V3 additionally makes use of a restricted routing mechanism to restrict communication costs throughout training. The 7B mannequin makes use of Multi-Head attention (MHA) while the 67B model makes use of Grouped-Query Attention (GQA). This overlap additionally ensures that, as the model additional scales up, as long as we maintain a constant computation-to-communication ratio, we are able to still make use of fine-grained specialists across nodes whereas achieving a near-zero all-to-all communication overhead.
Open-sourcing the new LLM for public research, free deepseek AI proved that their DeepSeek Chat is a lot better than Meta’s Llama 2-70B in numerous fields. Trying multi-agent setups. I having another LLM that can right the primary ones errors, or enter into a dialogue where two minds reach a greater final result is completely attainable. ARG occasions. Although DualPipe requires holding two copies of the mannequin parameters, this doesn't considerably enhance the reminiscence consumption since we use a big EP measurement throughout training. ARG affinity scores of the specialists distributed on each node. Slightly completely different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid operate to compute the affinity scores, and applies a normalization among all chosen affinity scores to supply the gating values. Like the machine-limited routing utilized by DeepSeek-V2, DeepSeek-V3 additionally makes use of a restricted routing mechanism to restrict communication costs throughout training. The 7B mannequin makes use of Multi-Head attention (MHA) while the 67B model makes use of Grouped-Query Attention (GQA). This overlap additionally ensures that, as the model additional scales up, as long as we maintain a constant computation-to-communication ratio, we are able to still make use of fine-grained specialists across nodes whereas achieving a near-zero all-to-all communication overhead.
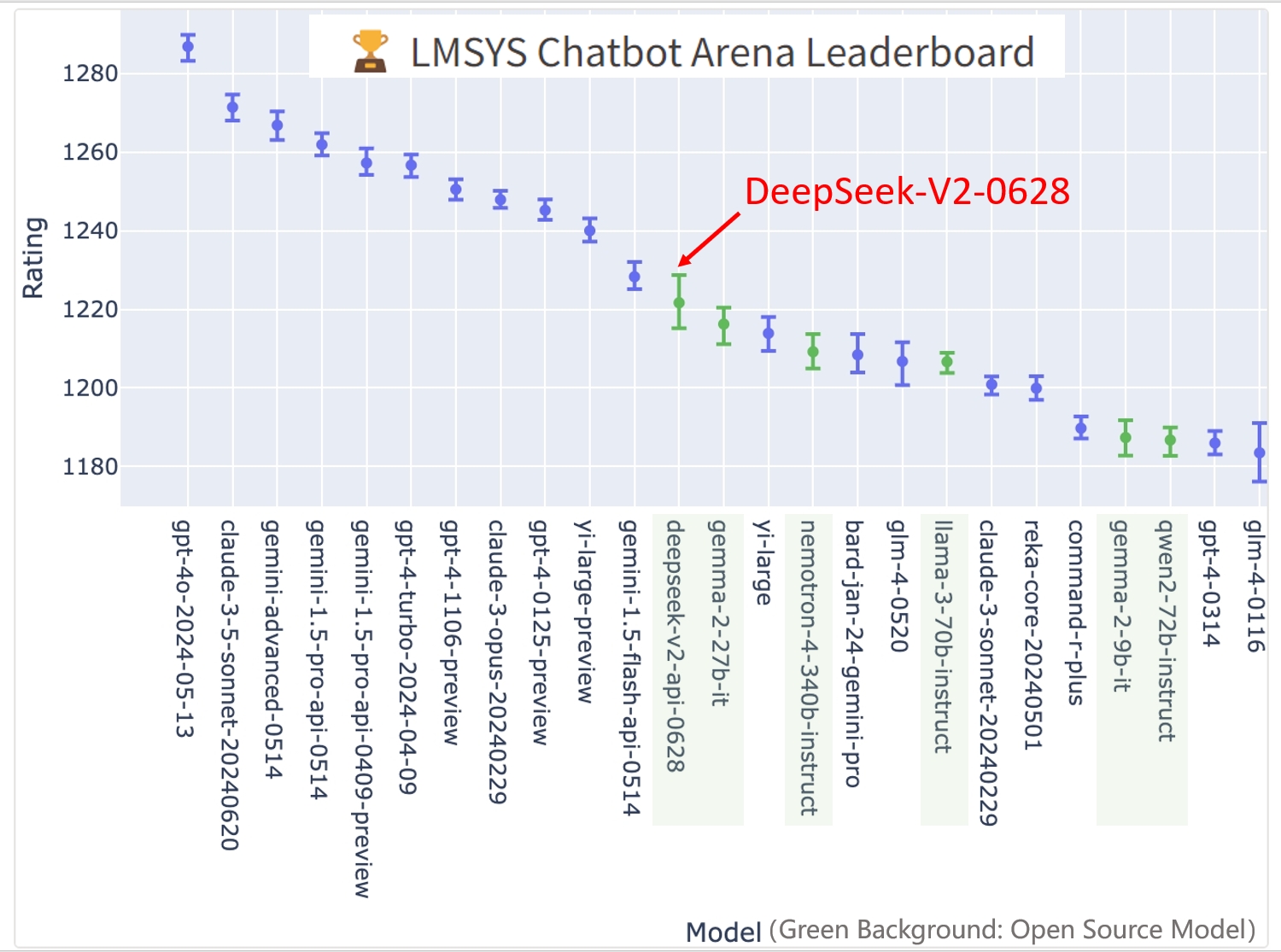 Each node in the H800 cluster incorporates eight GPUs linked by NVLink and NVSwitch inside nodes. The implementation of the kernels is co-designed with the MoE gating algorithm and the community topology of our cluster. DeepSeek-V3 is trained on a cluster outfitted with 2048 NVIDIA H800 GPUs. Through the dynamic adjustment, DeepSeek-V3 retains balanced expert load during coaching, and achieves better efficiency than fashions that encourage load steadiness by way of pure auxiliary losses. In order to ensure ample computational performance for DualPipe, we customise environment friendly cross-node all-to-all communication kernels (together with dispatching and combining) to conserve the variety of SMs devoted to communication. With a purpose to facilitate environment friendly training of DeepSeek-V3, we implement meticulous engineering optimizations. DeepSeek shows that plenty of the trendy AI pipeline will not be magic - it’s consistent good points accumulated on cautious engineering and choice making. Attributable to our efficient architectures and comprehensive engineering optimizations, DeepSeek-V3 achieves extraordinarily high training efficiency. Therefore, DeepSeek-V3 doesn't drop any tokens during training.
Each node in the H800 cluster incorporates eight GPUs linked by NVLink and NVSwitch inside nodes. The implementation of the kernels is co-designed with the MoE gating algorithm and the community topology of our cluster. DeepSeek-V3 is trained on a cluster outfitted with 2048 NVIDIA H800 GPUs. Through the dynamic adjustment, DeepSeek-V3 retains balanced expert load during coaching, and achieves better efficiency than fashions that encourage load steadiness by way of pure auxiliary losses. In order to ensure ample computational performance for DualPipe, we customise environment friendly cross-node all-to-all communication kernels (together with dispatching and combining) to conserve the variety of SMs devoted to communication. With a purpose to facilitate environment friendly training of DeepSeek-V3, we implement meticulous engineering optimizations. DeepSeek shows that plenty of the trendy AI pipeline will not be magic - it’s consistent good points accumulated on cautious engineering and choice making. Attributable to our efficient architectures and comprehensive engineering optimizations, DeepSeek-V3 achieves extraordinarily high training efficiency. Therefore, DeepSeek-V3 doesn't drop any tokens during training.
In addition, we additionally implement specific deployment strategies to ensure inference load steadiness, so DeepSeek-V3 also does not drop tokens during inference. Due to the efficient load balancing strategy, DeepSeek-V3 keeps a very good load steadiness throughout its full coaching. The sequence-sensible stability loss encourages the expert load on every sequence to be balanced. T represents the enter sequence length and i:j denotes the slicing operation (inclusive of each the left and proper boundaries). T denotes the number of tokens in a sequence. POSTSUPERSCRIPT denotes the output projection matrix. D additional tokens using unbiased output heads, we sequentially predict extra tokens and keep the entire causal chain at each prediction depth. Also, for every MTP module, its output head is shared with the primary mannequin. Note that for every MTP module, its embedding layer is shared with the principle mannequin. Note that the bias term is only used for routing. For MoE models, an unbalanced expert load will result in routing collapse (Shazeer et al., ديب سيك 2017) and diminish computational efficiency in scenarios with skilled parallelism. Under this constraint, our MoE coaching framework can practically achieve full computation-communication overlap.
Hence, after ok consideration layers, info can move forward by up to okay × W tokens SWA exploits the stacked layers of a transformer to attend information beyond the window measurement W . Specially, for a backward chunk, each attention and MLP are additional cut up into two elements, backward for input and backward for weights, like in ZeroBubble (Qi et al., 2023b). In addition, we've got a PP communication component. To be specific, we validate the MTP technique on top of two baseline models across different scales. A straightforward strategy is to apply block-sensible quantization per 128x128 elements like the way in which we quantize the model weights. Our MTP strategy mainly goals to enhance the performance of the principle mannequin, so throughout inference, we are able to instantly discard the MTP modules and the principle mannequin can function independently and usually. DeepSeek-Coder-V2 is an open-supply Mixture-of-Experts (MoE) code language mannequin that achieves performance comparable to GPT4-Turbo in code-specific duties. However, too large an auxiliary loss will impair the model performance (Wang et al., 2024a). To attain a better commerce-off between load stability and mannequin efficiency, we pioneer an auxiliary-loss-free deepseek load balancing technique (Wang et al., 2024a) to make sure load steadiness.
In case you loved this information and you would love to receive more information about ديب سيك i implore you to visit our own site.
- 이전글High Stakes Casino Download - An In Depth Anaylsis on What Works and What Doesn't 25.02.01
- 다음글The No. 1 Deepseek Mistake You're Making (and four Methods To repair It) 25.02.01
댓글목록
등록된 댓글이 없습니다.