
Deepseek May Not Exist!
페이지 정보

본문
 The server plans listed within the comparability table are perfectly optimized for DeepSeek AI internet hosting. We've more information that is still to be integrated to practice the fashions to perform higher across a wide range of modalities, now we have better data that can educate explicit classes in areas which are most vital for them to study, and we've got new paradigms that can unlock expert performance by making it in order that the models can "think for longer". We've got these models which can control computer systems now, write code, and surf the net, which implies they'll work together with anything that's digital, assuming there’s a good interface. Some, equivalent to Ege Erdill of Epoch AI, have argued that the H20’s price per performance is significantly beneath that of chips such as the H200 for frontier AI model coaching, however not frontier AI model inference. DeepSeek-Infer Demo: We provide a simple and lightweight demo for FP8 and BF16 inference. Free DeepSeek online is a complicated AI mannequin designed for a spread of applications, from natural language processing (NLP) tasks to machine studying inference and coaching. Put money into employee training to make sure a easy adoption of Deepseek's expertise and maximize its potential.
The server plans listed within the comparability table are perfectly optimized for DeepSeek AI internet hosting. We've more information that is still to be integrated to practice the fashions to perform higher across a wide range of modalities, now we have better data that can educate explicit classes in areas which are most vital for them to study, and we've got new paradigms that can unlock expert performance by making it in order that the models can "think for longer". We've got these models which can control computer systems now, write code, and surf the net, which implies they'll work together with anything that's digital, assuming there’s a good interface. Some, equivalent to Ege Erdill of Epoch AI, have argued that the H20’s price per performance is significantly beneath that of chips such as the H200 for frontier AI model coaching, however not frontier AI model inference. DeepSeek-Infer Demo: We provide a simple and lightweight demo for FP8 and BF16 inference. Free DeepSeek online is a complicated AI mannequin designed for a spread of applications, from natural language processing (NLP) tasks to machine studying inference and coaching. Put money into employee training to make sure a easy adoption of Deepseek's expertise and maximize its potential.
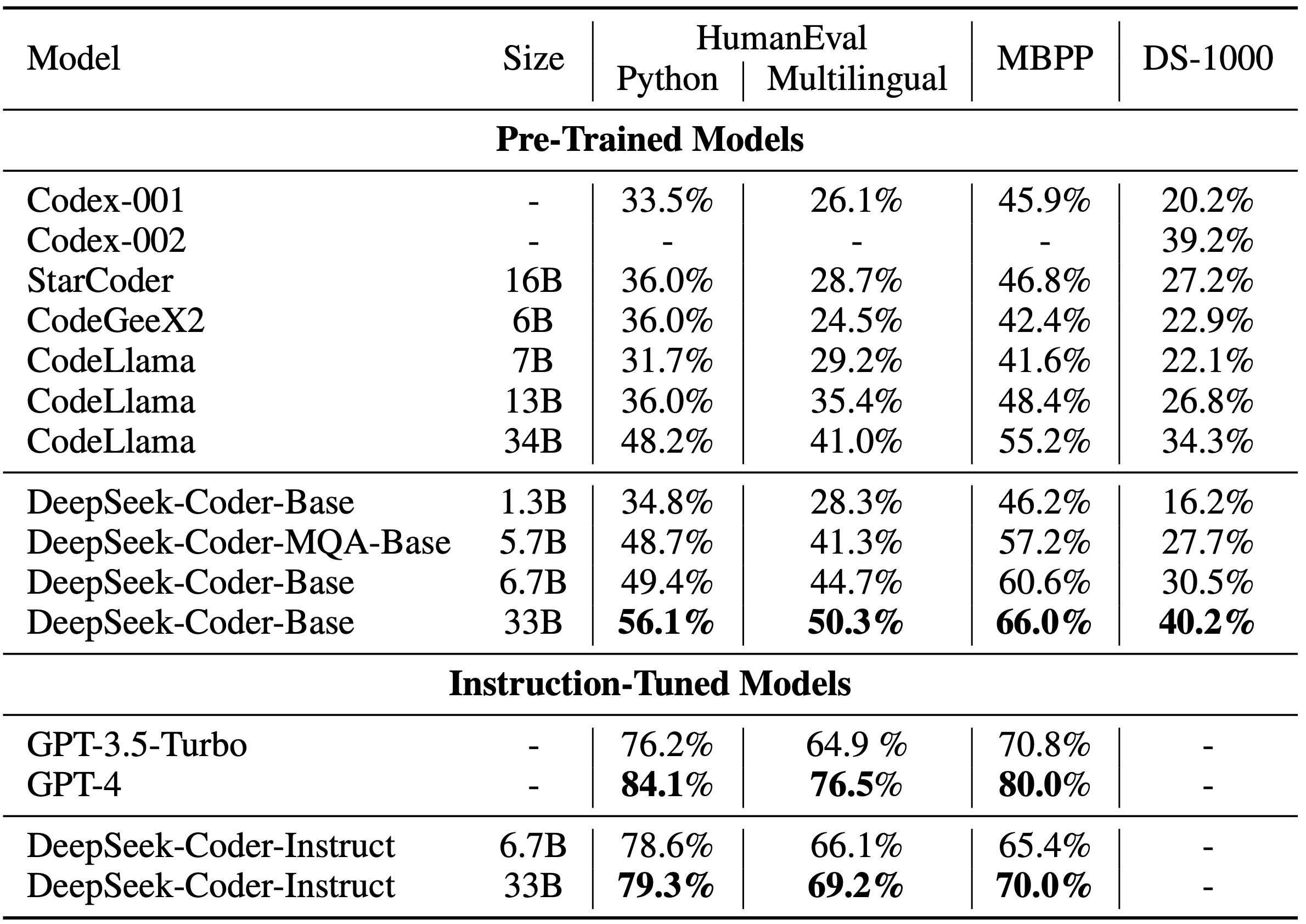
Temporal structured knowledge. Data across an enormous range of modalities, sure even with the current coaching of multimodal fashions, stays to be unearthed. The Achilles heel of current models is that they are really bad at iterative reasoning. One noticeable distinction within the models is their general data strengths. Artificial intelligence is evolving at an unprecedented tempo, and DeepSeek is certainly one of the most recent developments making waves in the AI panorama. The claims around DeepSeek and the sudden curiosity in the company have sent shock waves by the U.S. Many customers have encountered login difficulties or points when trying to create new accounts, because the platform has restricted new registrations to mitigate these challenges. Founded in 2023, the corporate claims it used simply 2,048 Nvidia H800s and USD5.6m to practice a model with 671bn parameters, a fraction of what Open AI and other firms have spent to train comparable measurement models, in response to the Financial Times. DeepSeek-Coder-6.7B is amongst DeepSeek Coder series of massive code language models, pre-trained on 2 trillion tokens of 87% code and 13% pure language text. We further conduct supervised tremendous-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base fashions, ensuing within the creation of DeepSeek Chat fashions.
With all this we should always imagine that the biggest multimodal models will get a lot (a lot) higher than what they are in the present day. It’s better, however not that much better. It’s a way to drive us to turn into better teachers, so as to show the models into higher students. And even if you happen to don’t totally imagine in switch learning you must think about that the models will get significantly better at having quasi "world models" inside them, enough to improve their efficiency quite dramatically. To make sure unbiased and thorough performance assessments, DeepSeek AI designed new downside units, such as the Hungarian National High-School Exam and Google’s instruction following the evaluation dataset. It is cheaper to create the data by outsourcing the performance of duties by means of tactile sufficient robots! Data on how we move world wide. And it’s onerous, because the real world is annoyingly sophisticated. It states that because it’s skilled with RL to "think for longer", and it may well only be trained to do so on effectively defined domains like maths or code, or the place chain of thought may be extra useful and there’s clear ground reality correct answers, it won’t get a lot better at other actual world solutions. OpenAI thinks it’s even possible for areas like legislation, and that i see no reason to doubt them.
See this current function on how it performs out at Tencent and NetEase. But seems that’s not true! It’s harder to be an engineering supervisor, than it has been in the course of the 2010-2022 interval, that’s for positive. AI and inexpensive, that’s good. More efficiency and decrease prices will certainly be good for the customers. Whether it’s writing place papers, or analysing math problems, or writing economics essays, or even answering NYT Sudoku questions, it’s actually actually good. Powered by the state-of-the-art DeepSeek-V3 model, it delivers precise and fast results, whether or not you’re writing code, fixing math issues, or producing artistic content. Analyze: Click the "Analyze" button to course of the content material. 3. Click on "Restore settings to their default values". 5. Click on "Finish". This amount also seems to solely mirror the cost of the existing coaching, so costs seem to be understated. However, evidently the very low price has been achieved via "distillation" or is a derivative of existing LLMs, with a concentrate on enhancing efficiency. As a result of its nation of origin, however, it’s unlikely that the Riot Games owner will discover cracking the worldwide market plain crusing.
- 이전글How The 10 Worst 100% Real Counterfeit Money Mistakes Of All Time Could Have Been Prevented 25.03.07
- 다음글9 . What Your Parents Teach You About Link Alternatif Gotogel 25.03.07
댓글목록
등록된 댓글이 없습니다.