
Nine Superb Deepseek Hacks
페이지 정보

본문
 The DeepSeek R1 technical report states that its fashions do not use inference-time scaling. These outcomes place DeepSeek R1 amongst the top-performing AI fashions globally. 2) On coding-related duties, DeepSeek-V3 emerges as the highest-performing mannequin for coding competition benchmarks, equivalent to LiveCodeBench, solidifying its place because the main model on this area. This approach comes at a value: stifling creativity, discouraging impartial drawback-solving, and ultimately hindering China’s capability to interact in long-time period innovation-based competition. This wave of innovation has fueled intense competitors amongst tech firms trying to turn into leaders in the sector. In the long run, AI corporations within the US and different democracies will need to have higher fashions than these in China if we wish to prevail. Alternatively, MTP might enable the mannequin to pre-plan its representations for higher prediction of future tokens. This overlap ensures that, as the mannequin additional scales up, so long as we maintain a continuing computation-to-communication ratio, we are able to nonetheless make use of fantastic-grained specialists throughout nodes while attaining a close to-zero all-to-all communication overhead. In addition, we additionally develop environment friendly cross-node all-to-all communication kernels to completely utilize InfiniBand (IB) and NVLink bandwidths. In addition, we also implement particular deployment methods to make sure inference load stability, so DeepSeek v3-V3 also doesn't drop tokens during inference.
The DeepSeek R1 technical report states that its fashions do not use inference-time scaling. These outcomes place DeepSeek R1 amongst the top-performing AI fashions globally. 2) On coding-related duties, DeepSeek-V3 emerges as the highest-performing mannequin for coding competition benchmarks, equivalent to LiveCodeBench, solidifying its place because the main model on this area. This approach comes at a value: stifling creativity, discouraging impartial drawback-solving, and ultimately hindering China’s capability to interact in long-time period innovation-based competition. This wave of innovation has fueled intense competitors amongst tech firms trying to turn into leaders in the sector. In the long run, AI corporations within the US and different democracies will need to have higher fashions than these in China if we wish to prevail. Alternatively, MTP might enable the mannequin to pre-plan its representations for higher prediction of future tokens. This overlap ensures that, as the mannequin additional scales up, so long as we maintain a continuing computation-to-communication ratio, we are able to nonetheless make use of fantastic-grained specialists throughout nodes while attaining a close to-zero all-to-all communication overhead. In addition, we additionally develop environment friendly cross-node all-to-all communication kernels to completely utilize InfiniBand (IB) and NVLink bandwidths. In addition, we also implement particular deployment methods to make sure inference load stability, so DeepSeek v3-V3 also doesn't drop tokens during inference.
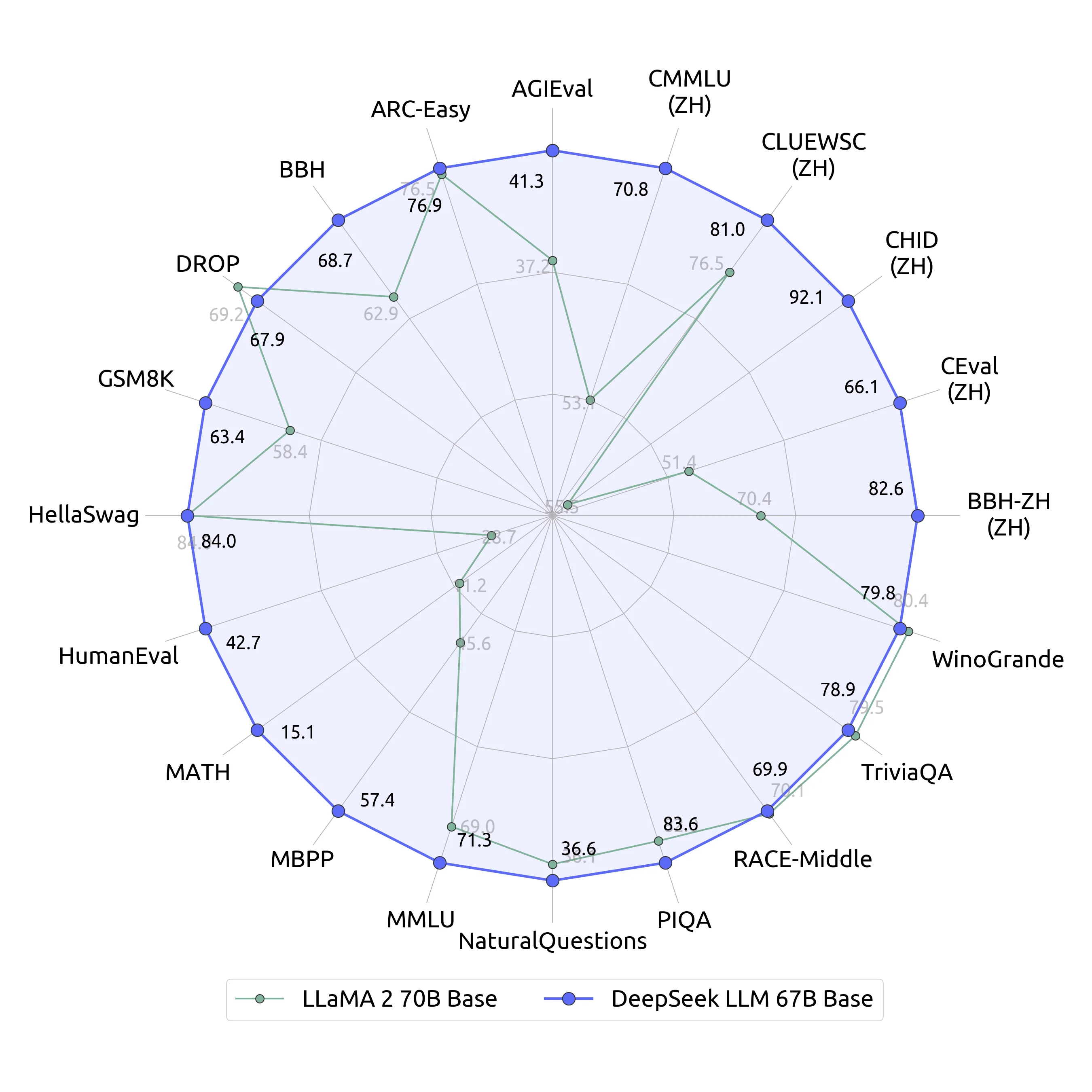
Therefore, DeepSeek-V3 does not drop any tokens during coaching. Through the help for FP8 computation and storage, we achieve each accelerated training and lowered GPU memory utilization. Furthermore, we meticulously optimize the memory footprint, making it doable to prepare DeepSeek-V3 without utilizing pricey tensor parallelism. For MoE fashions, an unbalanced expert load will lead to routing collapse (Shazeer et al., 2017) and diminish computational efficiency in situations with professional parallelism. On the one hand, an MTP objective densifies the coaching alerts and may enhance information effectivity. Our principle of sustaining the causal chain of predictions is much like that of EAGLE (Li et al., 2024b), however its major objective is speculative decoding (Xia et al., 2023; Leviathan et al., 2023), whereas we utilize MTP to enhance training. • We investigate a Multi-Token Prediction (MTP) goal and show it beneficial to model performance. 2) For factuality benchmarks, DeepSeek-V3 demonstrates superior performance among open-supply fashions on both SimpleQA and Chinese SimpleQA. Its chat version also outperforms different open-supply models and achieves efficiency comparable to leading closed-source fashions, together with GPT-4o and Claude-3.5-Sonnet, on a series of customary and open-ended benchmarks. These two architectures have been validated in DeepSeek-V2 (DeepSeek-AI, 2024c), demonstrating their functionality to keep up strong model efficiency while attaining efficient training and inference.
However, following their methodology, we for the first time uncover that two AI systems pushed by Meta’s Llama31-70B-Instruct and Alibaba’s Qwen25-72B-Instruct, well-liked large language fashions of much less parameters and weaker capabilities, have already surpassed the self-replicating crimson line. Consequently, our pre-training stage is accomplished in less than two months and costs 2664K GPU hours. Lastly, we emphasize once more the economical coaching costs of DeepSeek-V3, summarized in Table 1, achieved by way of our optimized co-design of algorithms, frameworks, and hardware. Low-precision training has emerged as a promising answer for efficient coaching (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being carefully tied to advancements in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). On this work, we introduce an FP8 blended precision coaching framework and, for the primary time, validate its effectiveness on an extremely giant-scale mannequin.
 Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the efficiency degradation induced by the effort to ensure load stability. DeepSeek R1 represents a groundbreaking development in synthetic intelligence, providing state-of-the-art efficiency in reasoning, arithmetic, and coding duties. T represents the enter sequence length and that i:j denotes the slicing operation (inclusive of both the left and right boundaries). The sequence-clever steadiness loss encourages the knowledgeable load on every sequence to be balanced. Because of the effective load balancing strategy, DeepSeek-V3 retains a very good load balance during its full coaching. Then, we present a Multi-Token Prediction (MTP) coaching objective, which we now have observed to reinforce the overall efficiency on analysis benchmarks. • Code, Math, and Reasoning: (1) DeepSeek-V3 achieves state-of-the-artwork efficiency on math-related benchmarks among all non-long-CoT open-supply and closed-source fashions. R1 is the latest of a number of AI models DeepSeek has made public. Almost all models had hassle coping with this Java specific language characteristic The majority tried to initialize with new Knapsack.Item(). The paper introduces DeepSeekMath 7B, a big language mannequin that has been particularly designed and educated to excel at mathematical reasoning.
Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the efficiency degradation induced by the effort to ensure load stability. DeepSeek R1 represents a groundbreaking development in synthetic intelligence, providing state-of-the-art efficiency in reasoning, arithmetic, and coding duties. T represents the enter sequence length and that i:j denotes the slicing operation (inclusive of both the left and right boundaries). The sequence-clever steadiness loss encourages the knowledgeable load on every sequence to be balanced. Because of the effective load balancing strategy, DeepSeek-V3 retains a very good load balance during its full coaching. Then, we present a Multi-Token Prediction (MTP) coaching objective, which we now have observed to reinforce the overall efficiency on analysis benchmarks. • Code, Math, and Reasoning: (1) DeepSeek-V3 achieves state-of-the-artwork efficiency on math-related benchmarks among all non-long-CoT open-supply and closed-source fashions. R1 is the latest of a number of AI models DeepSeek has made public. Almost all models had hassle coping with this Java specific language characteristic The majority tried to initialize with new Knapsack.Item(). The paper introduces DeepSeekMath 7B, a big language mannequin that has been particularly designed and educated to excel at mathematical reasoning.
- 이전글Asia Cruise - How To Maximize Your Holiday In 5 Easy Ways 25.03.07
- 다음글تعرفي على أهم 50 مدرب، ومدربة لياقة بدنية في 2025 25.03.07
댓글목록
등록된 댓글이 없습니다.