
???? DeepSeek-R1-Lite-Preview is Now Live: Unleashing Supercharged Rea…
페이지 정보

본문

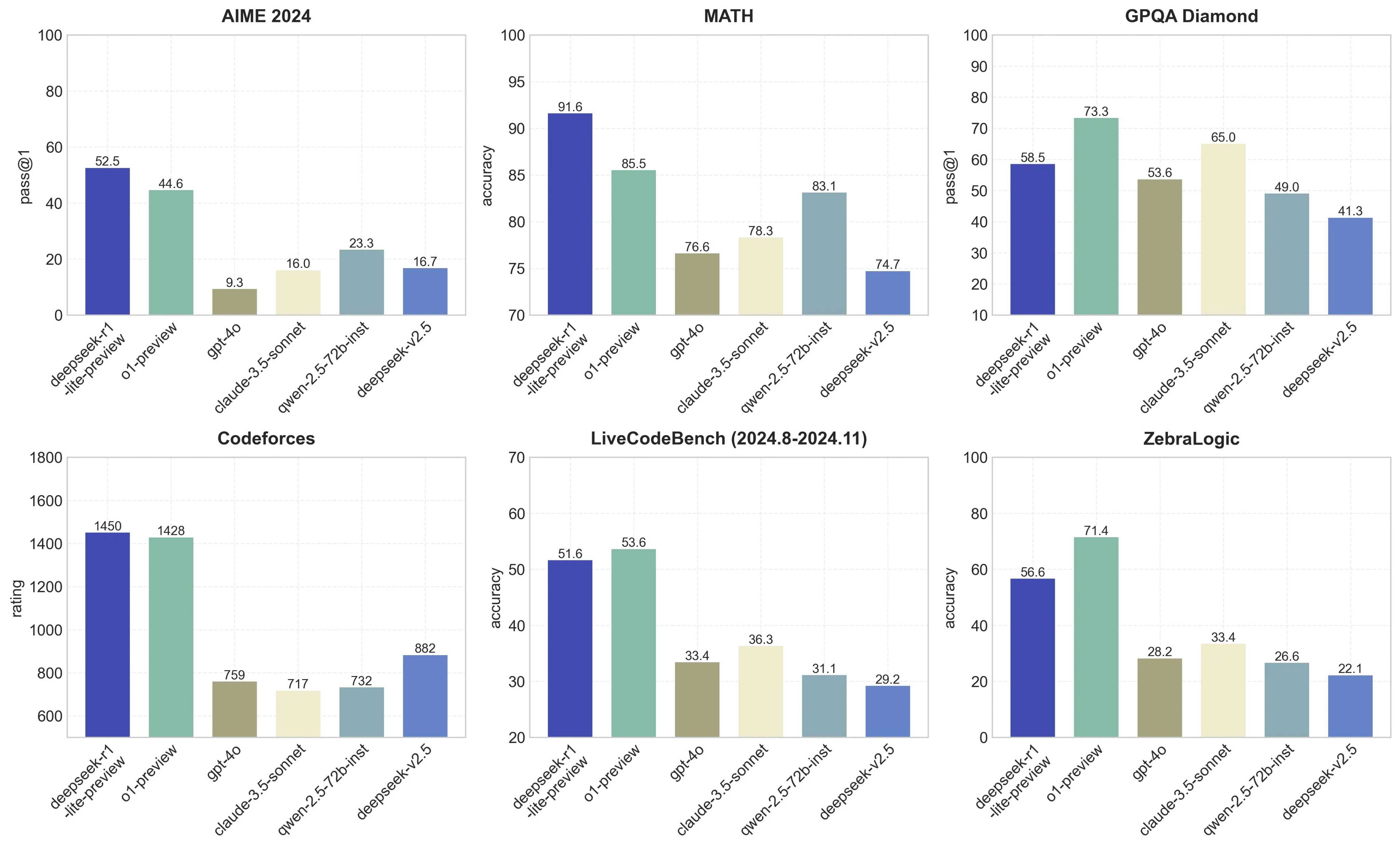 Its performance is comparable to main closed-supply fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the hole between open-supply and closed-supply models on this domain. Additionally, there’s a few twofold hole in information efficiency, which means we'd like twice the training data and computing power to achieve comparable outcomes. "This means we want twice the computing energy to realize the identical results. Why this issues - decentralized coaching might change quite a lot of stuff about AI coverage and energy centralization in AI: Today, influence over AI growth is determined by individuals that may access enough capital to acquire enough computer systems to practice frontier models. They’re also higher on an power viewpoint, producing much less heat, making them easier to power and integrate densely in a datacenter. We believe the pipeline will profit the business by creating better models. Researchers with University College London, Ideas NCBR, the University of Oxford, New York University, and Anthropic have constructed BALGOG, a benchmark for visual language models that assessments out their intelligence by seeing how nicely they do on a set of text-journey games. Get the benchmark right here: BALROG (balrog-ai, GitHub).
Its performance is comparable to main closed-supply fashions like GPT-4o and Claude-Sonnet-3.5, narrowing the hole between open-supply and closed-supply models on this domain. Additionally, there’s a few twofold hole in information efficiency, which means we'd like twice the training data and computing power to achieve comparable outcomes. "This means we want twice the computing energy to realize the identical results. Why this issues - decentralized coaching might change quite a lot of stuff about AI coverage and energy centralization in AI: Today, influence over AI growth is determined by individuals that may access enough capital to acquire enough computer systems to practice frontier models. They’re also higher on an power viewpoint, producing much less heat, making them easier to power and integrate densely in a datacenter. We believe the pipeline will profit the business by creating better models. Researchers with University College London, Ideas NCBR, the University of Oxford, New York University, and Anthropic have constructed BALGOG, a benchmark for visual language models that assessments out their intelligence by seeing how nicely they do on a set of text-journey games. Get the benchmark right here: BALROG (balrog-ai, GitHub).
""BALROG is troublesome to solve via simple memorization - all of the environments used in the benchmark are procedurally generated, and encountering the same occasion of an environment twice is unlikely," they write. Why this matters - textual content games are exhausting to learn and may require wealthy conceptual representations: Go and play a textual content journey sport and discover your own experience - you’re each studying the gameworld and ruleset whereas also building a wealthy cognitive map of the setting implied by the text and the visible representations. DeepSeek primarily took their present excellent mannequin, built a smart reinforcement learning on LLM engineering stack, then did some RL, then they used this dataset to show their model and different good fashions into LLM reasoning fashions. Read extra: BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games (arXiv). deepseek ai china-R1-Zero, a mannequin trained through giant-scale reinforcement learning (RL) with out supervised high quality-tuning (SFT) as a preliminary step, demonstrated outstanding efficiency on reasoning. DeepSeek also lately debuted DeepSeek-R1-Lite-Preview, a language mannequin that wraps in reinforcement studying to get higher efficiency.
Instruction-following analysis for big language models. Pretty good: They practice two types of model, a 7B and a 67B, then they evaluate efficiency with the 7B and 70B LLaMa2 models from Facebook. They'd made no try to disguise its artifice - it had no defined options in addition to two white dots the place human eyes would go. Then he opened his eyes to take a look at his opponent. Inside he closed his eyes as he walked in the direction of the gameboard. The resulting dataset is more various than datasets generated in more mounted environments. Finally, we're exploring a dynamic redundancy strategy for consultants, where each GPU hosts extra specialists (e.g., Sixteen experts), but only 9 will likely be activated during every inference step. We're also exploring the dynamic redundancy technique for decoding. Auxiliary-loss-free load balancing technique for mixture-of-specialists. LLM: Support DeepSeek-V3 model with FP8 and BF16 modes for tensor parallelism and pipeline parallelism.
When you loved this article and you would like to receive much more information with regards to ديب سيك kindly visit our own web site.
- 이전글5 Asbestos Mesothelioma Myths You Should Stay Clear Of 25.02.01
- 다음글كيفية ترتيب دولاب المطبخ أفكار وارشادات 25.02.01
댓글목록
등록된 댓글이 없습니다.